
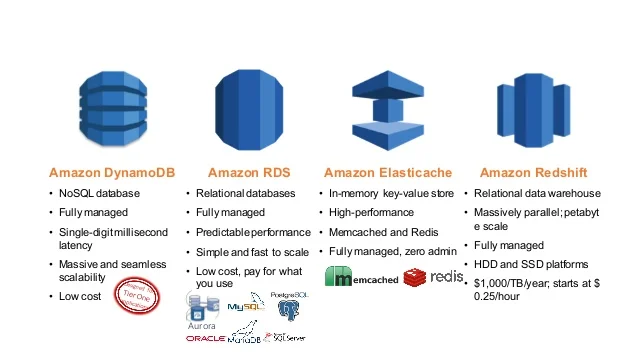
Redshift vs DynamoDB: Choosing The Right Database
In today’s data-driven world, choosing the right database solution is paramount. Amazon Web Services (AWS) offers two prominent options: Amazon Redshift and Amazon DynamoDB. Understanding the nuances of each can make or break your data architecture strategy. Let’s delve into the intricacies of Redshift vs. DynamoDB and help you make an informed decision.
Redshift: Scaling the Data Warehouse Heights
Key Features and Strengths
Amazon Redshift is a columnar-based data warehousing service designed to handle large datasets and complex queries with remarkable speed. Its strengths include:
- Massive Parallel Processing (MPP): Redshift distributes queries across multiple nodes, allowing it to process vast amounts of data concurrently. This ensures lightning-fast query execution even on massive datasets;
- Columnar Storage: Data is stored in columns rather than rows, optimizing query performance by fetching only the necessary columns, reducing I/O overhead.
Use Cases
Redshift shines when handling complex analytical queries and business intelligence reporting. It’s ideal for scenarios such as:
- Data Analytics: Redshift’s MPP architecture accelerates data analysis, enabling real-time insights from terabytes of data;
- Complex Queries: Businesses requiring intricate data manipulations benefit from Redshift’s query optimization capabilities;
- Historical Analysis: Long-term data storage and analysis are streamlined through Redshift’s efficient compression techniques.

DynamoDB: Navigating NoSQL Territory
Key Features and Strengths
Amazon DynamoDB, on the other hand, is a NoSQL database service that offers seamless scalability and low-latency performance. Its strengths include:
- Flexible Scalability: DynamoDB scales effortlessly with demand, accommodating fluctuating workloads without compromising performance;
- Low-Latency Access: DynamoDB’s single-digit millisecond response times make it perfect for applications requiring rapid data retrieval.
Use Cases
DynamoDB is tailor-made for scenarios demanding high-performance and scalability in real-time data access:
- Web Applications: E-commerce sites experience varying traffic; DynamoDB’s scalability ensures a consistent user experience;
- Gaming: Multiplayer games with dynamic player counts leverage DynamoDB’s ability to handle concurrent read and write operations efficiently.

Comparing Redshift and DynamoDB
Here’s a side-by-side comparison of their key aspects:
| Aspect | Amazon Redshift | Amazon DynamoDB |
|---|---|---|
| Data Model | Relational | NoSQL (Document) |
| Query Language | SQL | NoSQL (JSON-like) |
| Scalability | Vertical Scaling | Horizontal Scaling |
| Use Cases | Complex Analytics | Real-time Applications |
| Performance | Aggregations, Reporting | Rapid Data Retrieval |
Performance and Scalability: Unraveling the Metrics
Redshift’s Performance Metrics
Amazon Redshift’s performance metrics are designed to deliver optimal results for analytical workloads:
- Throughput: Redshift offers impressive query throughput due to its MPP architecture, enabling parallel processing of queries across multiple nodes;
- Aggregations: Complex aggregations are Redshift’s forte. It can swiftly aggregate and process large datasets, making it a powerhouse for business intelligence;
- Concurrency: Redshift’s ability to handle multiple concurrent queries efficiently is crucial for organizations dealing with simultaneous data analysis tasks.
DynamoDB’s Scalability Feat
DynamoDB’s scalability is centered around the following metrics:
- Auto Scaling: DynamoDB automatically scales based on demand, adjusting read and write capacities to match workload fluctuations;
- Partitioning: Its partitioning strategy allows for even distribution of data and efficient parallel processing of queries, resulting in consistent performance;
- Response Times: The single-digit millisecond response times are ideal for applications requiring rapid interactions, ensuring a smooth user experience.
Data Modeling Approaches: Tailoring to Your Data
Redshift’s Relational Model
Amazon Redshift employs a relational data model, which excels in scenarios where data relationships are structured:
- Schema Design: Redshift’s support for schemas and relationships simplifies data organization, making it suitable for complex data sets;
- Joins and Normalization: Its SQL capabilities facilitate complex joins and normalization, making it optimal for intricate queries and data relationships.
DynamoDB’s NoSQL Flexibility
DynamoDB’s NoSQL nature offers distinct advantages:
- Schemaless Design: NoSQL databases like DynamoDB offer flexibility for evolving data structures without rigid schema requirements;
- JSON-Like Documents: The document-based model, akin to JSON, makes it easy to store semi-structured or unstructured data.
Data Consistency: A Closer Look
Redshift’s Consistency Approach
Amazon Redshift emphasizes eventual consistency, ensuring that all replicas are updated eventually. This makes it suitable for analytical workloads where consistency can be relaxed for performance gains.
DynamoDB’s Strong Consistency
DynamoDB focuses on strong consistency, guaranteeing that all replicas are updated before a successful response is sent to the client. This ensures reliable data access for real-time applications.
Integrations and Ecosystem: Beyond the Database
Redshift’s Integration Landscape
Amazon Redshift seamlessly integrates with various analytics and visualization tools, including Amazon QuickSight, Tableau, and more. This makes it easier to extract meaningful insights from your data.
DynamoDB’s Ecosystem Flexibility
DynamoDB’s integration capabilities extend to AWS Lambda, enabling serverless data processing. It also integrates well with AWS IoT for managing IoT data, solidifying its place in the IoT landscape.
Data Security and Compliance: Protecting Your Assets
Redshift’s Security Features
Amazon Redshift offers robust security measures to safeguard your data:
- Encryption: Redshift supports encryption at rest and in transit, ensuring your data remains confidential;
- Access Control: Fine-grained access control through IAM roles and policies enables secure data management;
- Auditing: Redshift’s logging and auditing capabilities help track data access and changes, aiding compliance efforts.
DynamoDB’s Security Measures
DynamoDB also prioritizes data security with these features:
- Encryption: Encryption at rest and in transit guarantees the privacy of your data throughout its lifecycle;
- Access Control: IAM integration allows you to control who can access your DynamoDB resources, bolstering data protection;
- Global Tables Security: For globally distributed data, DynamoDB’s multi-region replication maintains security and consistency.
Cost Considerations: Balancing Your Budget
Redshift’s Pricing Model
Redshift’s pricing factors in data storage, query complexity, and data transfer costs:
- Storage: You pay for the amount of data stored, including backups and snapshots;
- Compute: Query complexity and execution time contribute to your compute costs;
- Data Transfer: Transferring data in and out of Redshift incurs data transfer charges.
DynamoDB’s Cost Structure
DynamoDB’s pricing revolves around provisioned capacity and on-demand pricing:
- Provisioned Capacity: You pay for the read and write capacity units provisioned, regardless of usage;
- On-Demand Pricing: Pay per request for read and write operations, suitable for variable workloads;
- Data Transfer: Similar to Redshift, data transfer costs apply when moving data in and out of DynamoDB.
Backup and Recovery Strategies: Ensuring Data Resilience
Redshift’s Backup Options
Amazon Redshift offers multiple backup solutions for data protection:
- Automated Backups: Regular snapshots of your cluster are taken automatically, providing point-in-time recovery options;
- Manual Snapshots: You can manually create snapshots for specific instances, preserving important states of your data;
- Cluster Restore: Redshift allows you to restore a cluster to a previous state using automated or manual snapshots.
DynamoDB’s Backup Capabilities
DynamoDB ensures data durability and recovery with these features:
- Continuous Backup: DynamoDB maintains continuous backups for point-in-time recovery;
- On-Demand Backup: Create backups manually, allowing you to capture specific data states;
- Point-in-Time Recovery: Restore your table to any point in time within a specified retention period.
Conclusion
In the realm of data management, choosing between Amazon Redshift and DynamoDB depends on your specific needs. Redshift excels in handling complex analytical queries and large-scale historical data analysis. In contrast, DynamoDB triumphs in scenarios demanding real-time, low-latency data access with seamless scalability.




Leave a Reply